Chaos engineering with the Snow Monkey
Nihonzaru (the Snow Monkey) is the chaos engineering tool provided by Otoroshi. You can access it at Settings (cog icon) / Snow Monkey.
Chaos engineering
Otoroshi offers some tools to introduce chaos engineering in your everyday life. With chaos engineering, you will improve the resilience of your architecture by creating faults in production on running systems. With Nihonzaru (the snow monkey) Otoroshi helps you to create faults on http request/response handled by Otoroshi.
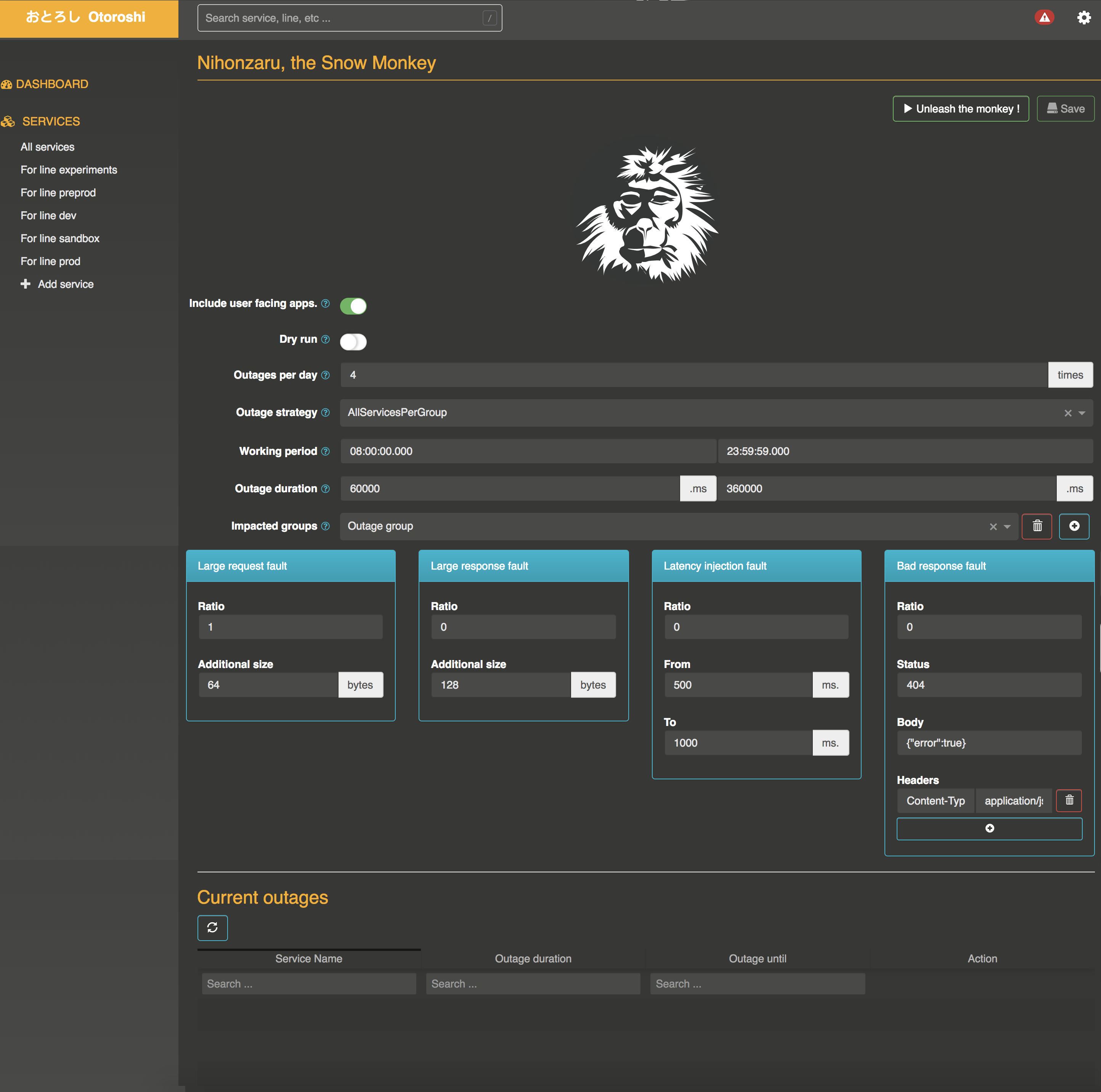
Settings
The snow monkey let you define a few settings to work properly :
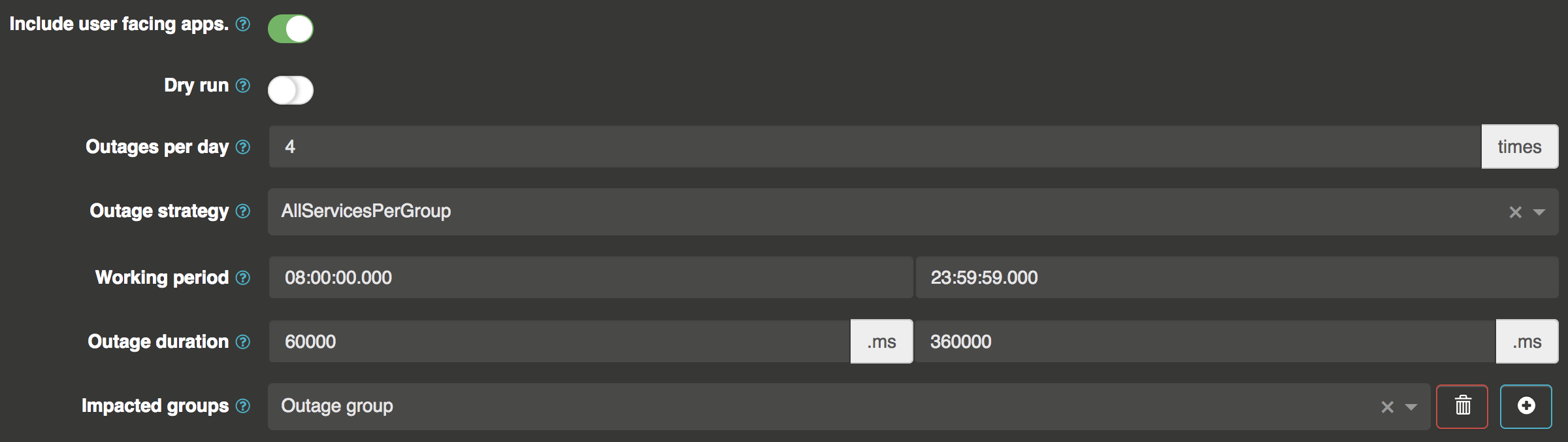
- Include user facing apps.: you want to create fault in production, but maybe you don’t want your users to enjoy some nice snow monkey generated error pages. Using this switch let you include of not user facing apps (ui apps). Each service descriptor has a
User facing app switchthat will be used by the snow monkey. - Dry run: when dry run is enabled, outages will be registered and will generate events and alerts (in the otoroshi eventing system) but requests won’t be actualy impacted. It’s a good way to prepare applications to the snow monkey habits
- Outage strategy: Either
AllServicesPerGrouporOneServicePerGroup. It means that only one service per group or all services per groups will havenoutages (see next bullet point) during the snow monkey working period - Outages per day: during snow monkey working period, each service per group or one service per group will have only
noutages registered - Working period: the snow monkey only works during a working period. Here you can defined when it starts and when it stops
- Outage duration: here you can defined the bounds for the random outage duration when an outage is created on a service
- Impacted groups: here you can define a list of service groups impacted by the snow monkey. If none is specified, then all service groups will be impacted
Faults
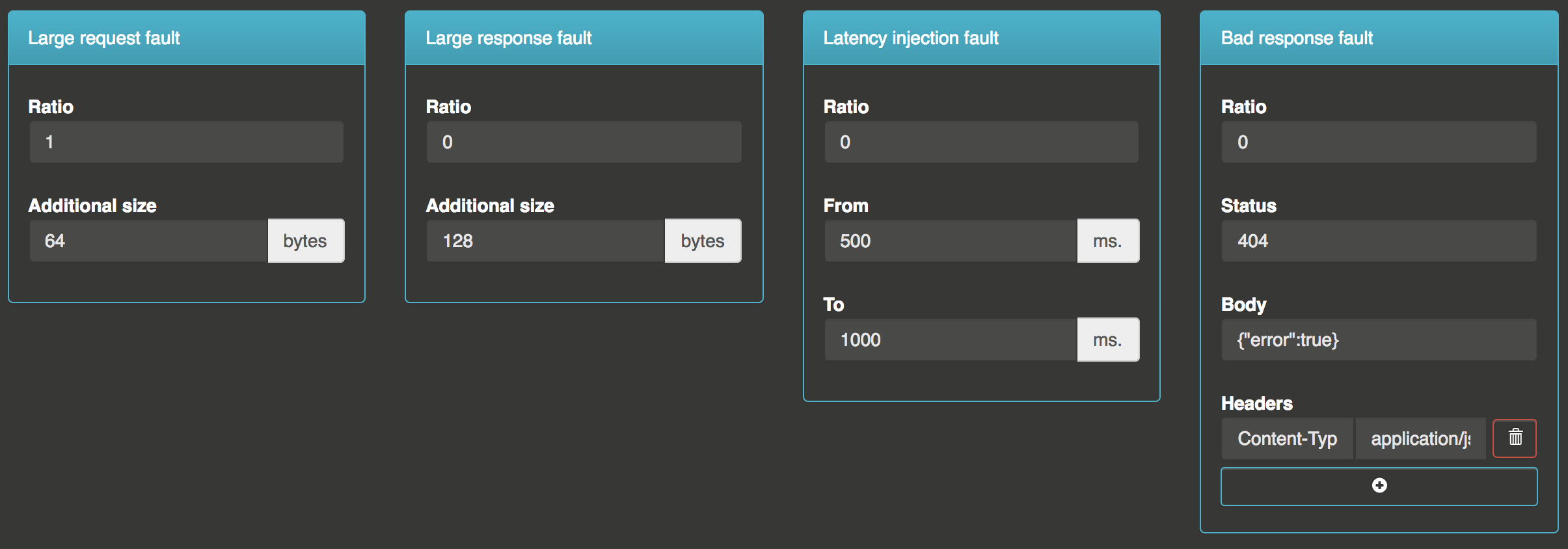
With the snow monkey, you can generate four types of faults
- Large request fault: Add trailing bytes at the end of the request body (if one)
- Large response fault: Add trailing bytes at the end of the response body
- Latency injection fault: Add random response latency between two bounds
- Bad response injection fault: Create predefined responses with custom headers, body and status code
Each fault let you define a ratio for impacted requests. If you specify a ratio of 0.2, then 20% of the requests for the impacte service will be impacted by this fault
Then you juste have to start the snow monkey and enjoy the show ;)

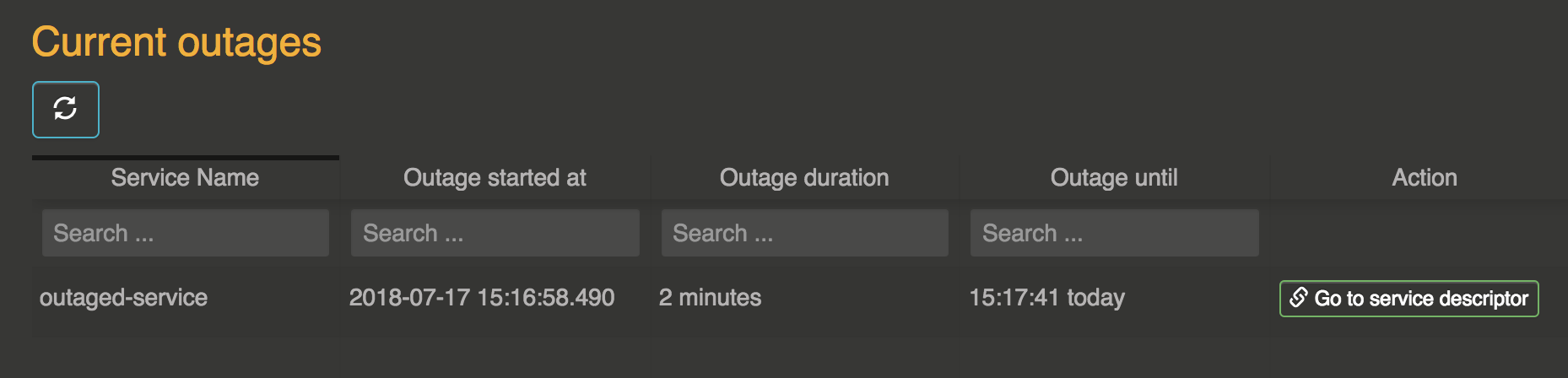
Current outages
In the last section of the snow monkey page, you can see current outages (per service), when they started, their duration, etc …